
🧩 Senior Thesis Project: Federated Learning Algorithm Exploiting Consensus ADMM for Enhanced Non-Convex Optimization
Date:
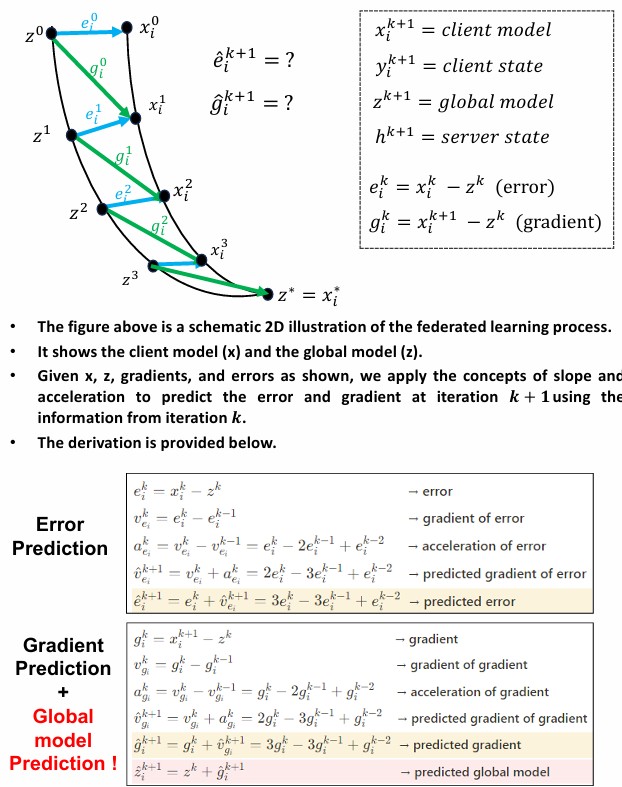
FedGP is a federated learning algorithm designed to accelerate convergence and improve accuracy by predicting future gradients. By modeling the training process as a 2D optimization problem and introducing the concepts of velocity and acceleration under the assumption of constant acceleration, FedGP predicts the gradient of the next iteration and incorporates it into the client update. This gradient prediction strategy enables faster convergence compared to existing methods such as FedDyn and FedAND, while maintaining competitive test accuracy. An extension, FedGP-PB, further applies the PowerBall function to stabilize the client state update, leading to significantly improved convergence and robustness under different participation rates and data distributions. Experiments on CIFAR-10 and MNIST demonstrated that FedGP achieves the fastest convergence rate, although challenges remain in handling divergence at full participation and in extending the method to large-scale client scenarios. This project highlights the potential of prediction-based strategies for advancing scalable and efficient federated learning.